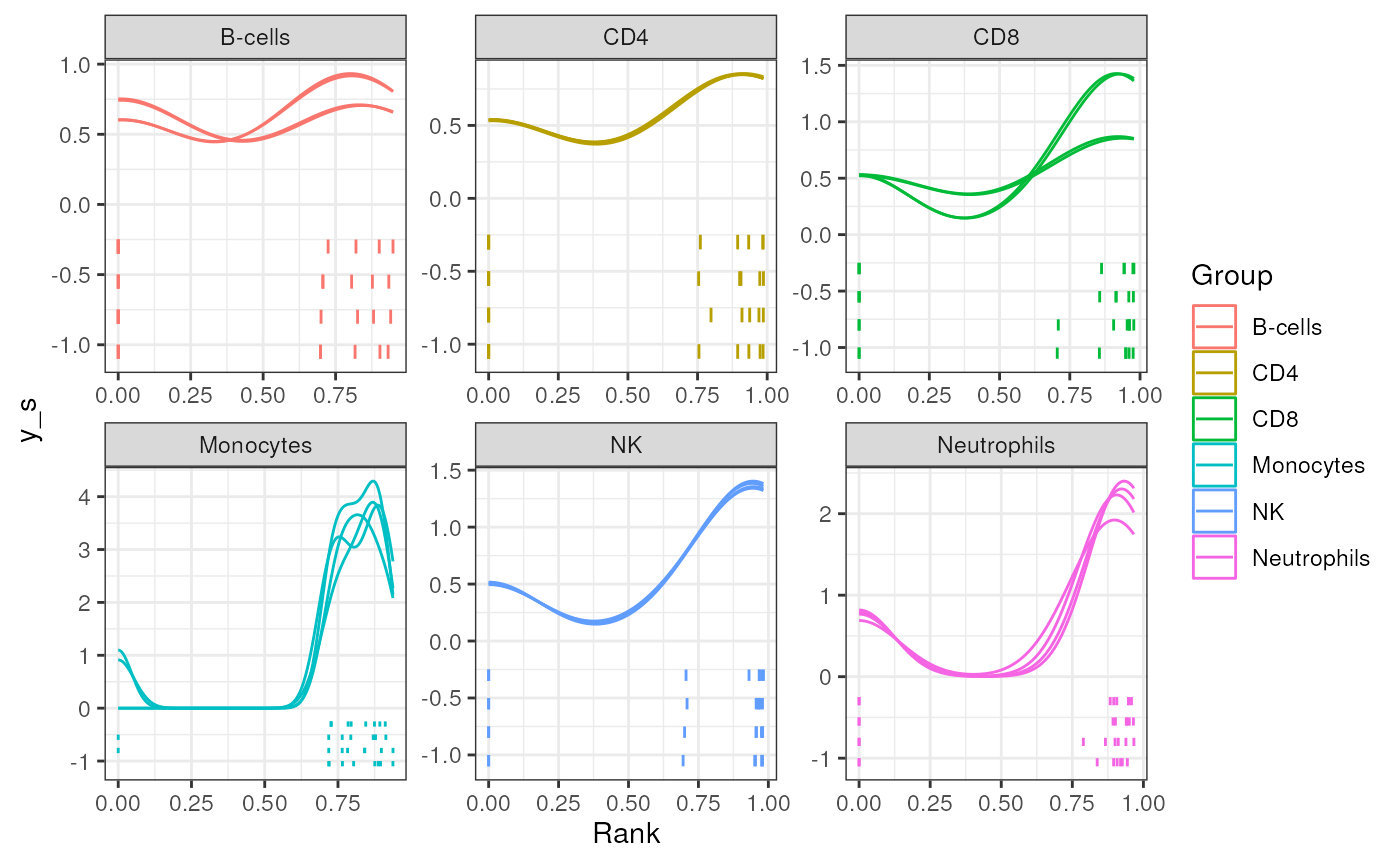
Show the rank density of given signature in the given comparison.
sig_rankdensity_plot(
data,
sigs,
group_col,
aggregate = FALSE,
slot = "counts",
gene_id = "SYMBOL"
)
# S4 method for matrix,vector,vector
sig_rankdensity_plot(
data,
sigs,
group_col,
aggregate = FALSE,
gene_id = "SYMBOL"
)
# S4 method for Matrix,vector,vector
sig_rankdensity_plot(
data,
sigs,
group_col,
aggregate = FALSE,
gene_id = "SYMBOL"
)
# S4 method for data.frame,vector,vector
sig_rankdensity_plot(
data,
sigs,
group_col,
aggregate = FALSE,
gene_id = "SYMBOL"
)
# S4 method for DGEList,vector,character
sig_rankdensity_plot(
data,
sigs,
group_col,
aggregate = FALSE,
slot = "counts",
gene_id = "SYMBOL"
)
# S4 method for ExpressionSet,vector,character
sig_rankdensity_plot(
data,
sigs,
group_col,
aggregate = FALSE,
gene_id = "SYMBOL"
)
# S4 method for Seurat,vector,character
sig_rankdensity_plot(
data,
sigs,
group_col,
aggregate = FALSE,
slot = "counts",
gene_id = "SYMBOL"
)
# S4 method for SummarizedExperiment,vector,character
sig_rankdensity_plot(
data,
sigs,
group_col,
aggregate = FALSE,
slot = "counts",
gene_id = "SYMBOL"
)
# S4 method for list,vector,character
sig_rankdensity_plot(
data,
sigs,
group_col,
aggregate = FALSE,
slot = "counts",
gene_id = "SYMBOL"
)Arguments
- data
expression data, can be matrix, DGEList, eSet, seurat, sce...
- sigs
a vector of signature (Symbols)
- group_col
character or vector, specify the column name to compare in coldata
- aggregate
logical, if to aggregate expression according to
group_col, default FALSE- slot
character, indicate which slot used as expression, optional
- gene_id
character, indicate the ID type of rowname of expression data's , could be one of 'ENSEMBL', 'SYMBOL', ... default 'SYMBOL'
Value
ggplot or patchwork
Examples
data("im_data_6", "nk_markers")
sig_rankdensity_plot(
data = im_data_6, sigs = nk_markers$HGNC_Symbol[1:10],
group_col = "celltype:ch1", gene_id = "ENSEMBL"
)
#> 'select()' returned 1:many mapping between keys and columns